 超算云
超算云 AI智算云
AI智算云文心4.5開源 × 北京超算:無界“模”力,即刻開跑!
6月30日,百度正式開源文心大模型4.5系列模型,作為文心開源模型平臺伙伴,北京超算AI智算云平臺在開源首日即打通云端部署鏈路,在“模型及服務(MaaS)”平臺大模型廣場上線文心開源4.5系列模型,為開發者們打造“算力驅動型”大模型落地新范式。
文心4.5系列模型開源說明及能力
此次文心4.5系列開源模型共10款,涵蓋了激活參數規模分別為47B和3B的混合專家(MoE)模型(最大的模型總參數量為424B),以及0.3B的稠密參數模型。
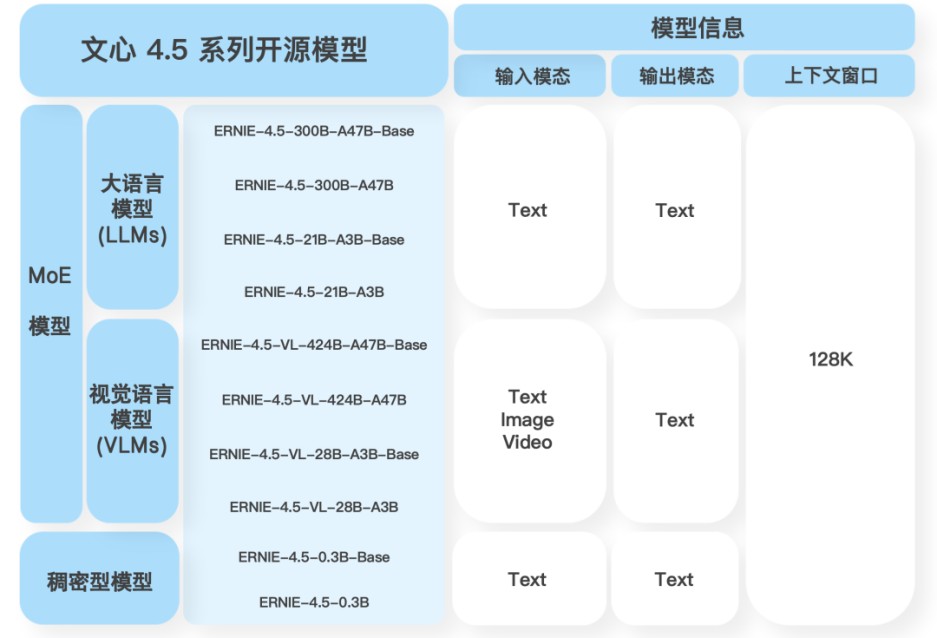
針對 MoE 架構,百度提出了一種創新性的多模態異構模型結構,通過跨模態參數共享機制實現模態間知識融合,同時為各單一模態保留專用參數空間。此架構非常適用于從大語言模型向多模態模型的持續預訓練范式,在保持甚至提升文本任務性能的基礎上,顯著增強多模態理解能力。
文心4.5系列模型均使用飛槳深度學習框架進行高效訓練、推理和部署。根據百度公開的測試結果,在大語言模型的預訓練中,模型FLOPs利用率(MFU)達到47%。實驗結果顯示,該系列模型在多個文本和多模態基準測試中達到SOTA水平,在指令遵循、世界知識記憶、視覺理解和多模態推理任務上效果尤為突出。模型權重按照Apache 2.0協議開源,支持開展學術研究和產業應用。此外,基于飛槳提供開源的產業級開發套件,廣泛兼容多種芯片,降低后訓練和部署門檻。
文心4.5系列開源模型核心技術亮點

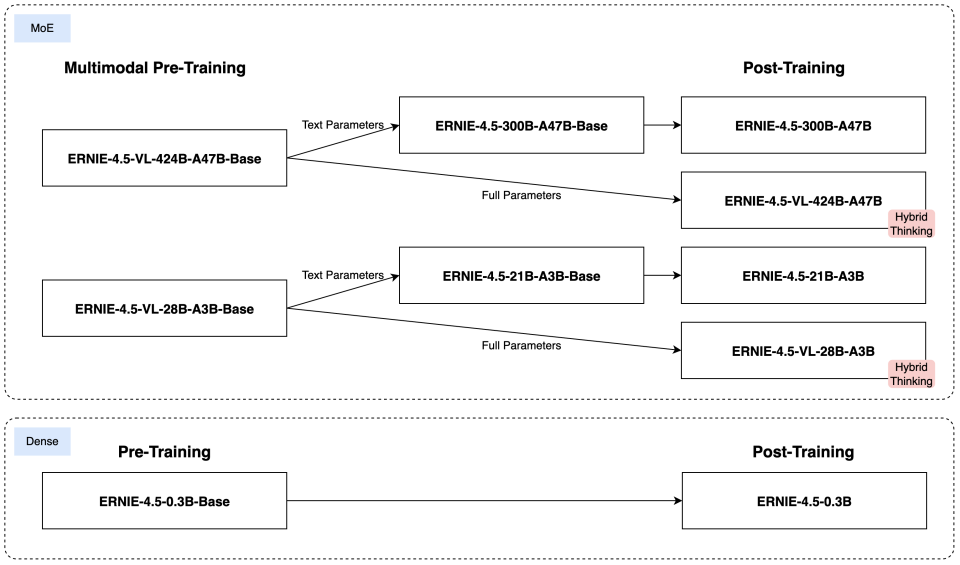
01 多模態混合專家模型預訓練
文心4.5通過在文本和視覺兩種模態上進行聯合訓練,更好地捕捉多模態信息中的細微差別,提升在文本生成、圖像理解以及多模態推理等任務中的表現。為了讓兩種模態學習時互相提升,百度提出了一種多模態異構混合專家模型結構,結合了多維旋轉位置編碼,并且在損失函數計算時,增強了不同專家間的正交性,同時對不同模態間的詞元進行平衡優化,達到多模態相互促進提升的目的。
02 高效訓練推理框架
為了支持文心4.5模型的高效訓練,百度提出了異構混合并行和多層級負載均衡策略。通過節點內專家并行、顯存友好的流水線調度、FP8混合精度訓練和細粒度重計算等多項技術,顯著提升了預訓練吞吐。推理方面,百度提出了多專家并行協同量化方法和卷積編碼量化算法,實現了效果接近無損的4-bit量化和2-bit量化。此外,百度還實現了動態角色轉換的預填充、解碼分離部署技術,可以更充分地利用資源,提升文心4.5 MoE模型的推理性能。基于飛槳框架,文心4.5在多種硬件平臺均表現出優異的推理性能。
03 針對模態的后訓練
為了滿足實際場景的不同要求,百度對預訓練模型進行了針對模態的精調。其中,大語言模型針對通用語言理解和生成進行了優化,多模態大模型側重于視覺語言理解,支持思考和非思考模式。每個模型采用了SFT、DPO或UPO(Unified Preference Optimization,統一偏好優化技術)的多階段后訓練。
馬上登錄ai.blsc.cn
體驗文心4.5超能“模”力
【API申請及使用步驟】
1.登錄北京超算AI智算云-大模型平臺https://ai.blsc.cn/#/lms/model
2.打開【模型廣場】,選擇文心模型,點擊“申請API”即可跳轉至API密鑰創建頁面,密鑰可支持本平臺所有模型~
注:可點擊申請Tokens后免費體驗~
3.選擇Chatbox、Cherry Studio、代碼接入等多種使用方式,均可完成接入使用~
詳細接入手冊,可參考平臺【大模型平臺使用指南-API使用文檔】
無界“模”力,即刻開跑!
百度文心開源,開放生態邁出關鍵一步。北京超算以首日接入的迅捷響應,彰顯平臺級伙伴的擔當。依托超算架構的算力融合調度優勢與千卡級集群服務經驗,北京超算AI智算云平臺將為文心模型提供高質量、高性能、高性價比的算力服務支持。開發者無需擔憂硬件適配與資源瓶頸,即可調用文心領先的多模態理解與復雜推理能力,專注場景創新。這種“開放模型+共享算力”的雙輪驅動,正加速打破AI落地的藩籬——讓前沿的模型,跑在高效的算力之上;讓最靈感的創造,獲得最堅實的支撐。
無界“模”力,即刻開跑!中國AI創新的燎原之勢已然可期,北京超算將與百度飛槳及廣大開發者并肩,以開放、協同、共贏之姿,共拓大模型賦能的千行百業!






